Stop Piloting.
Start Scaling. 


95% of AI pilots fail due to poor execution.
We turn AI into a business discipline with distinct bottlenecks and measurable KPIs.


We turn ambiguous AI ideas into production features your users trust—combining strategy, design, engineering, and rigorous evaluation.

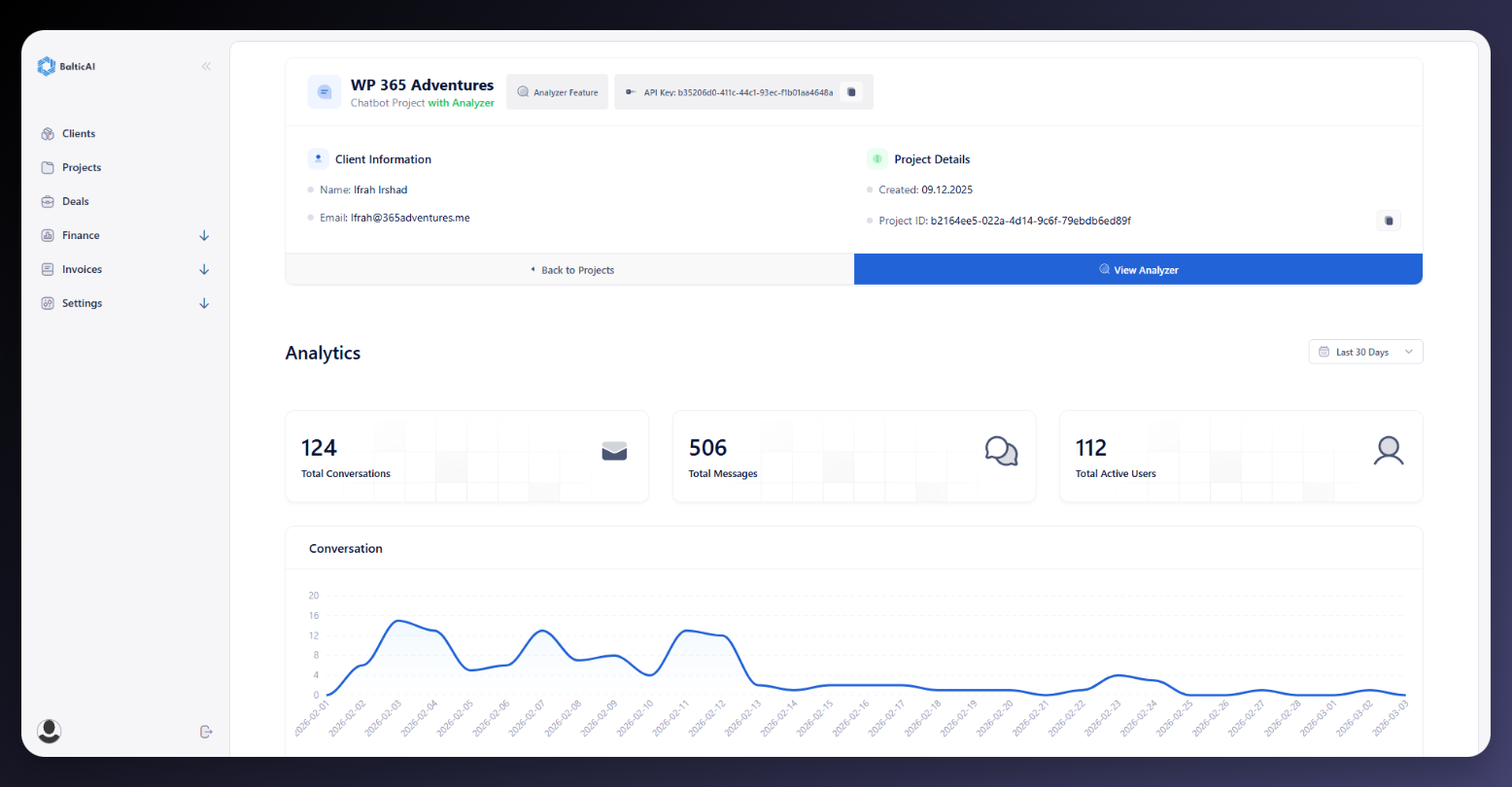
Services Dashboard for AI Ops
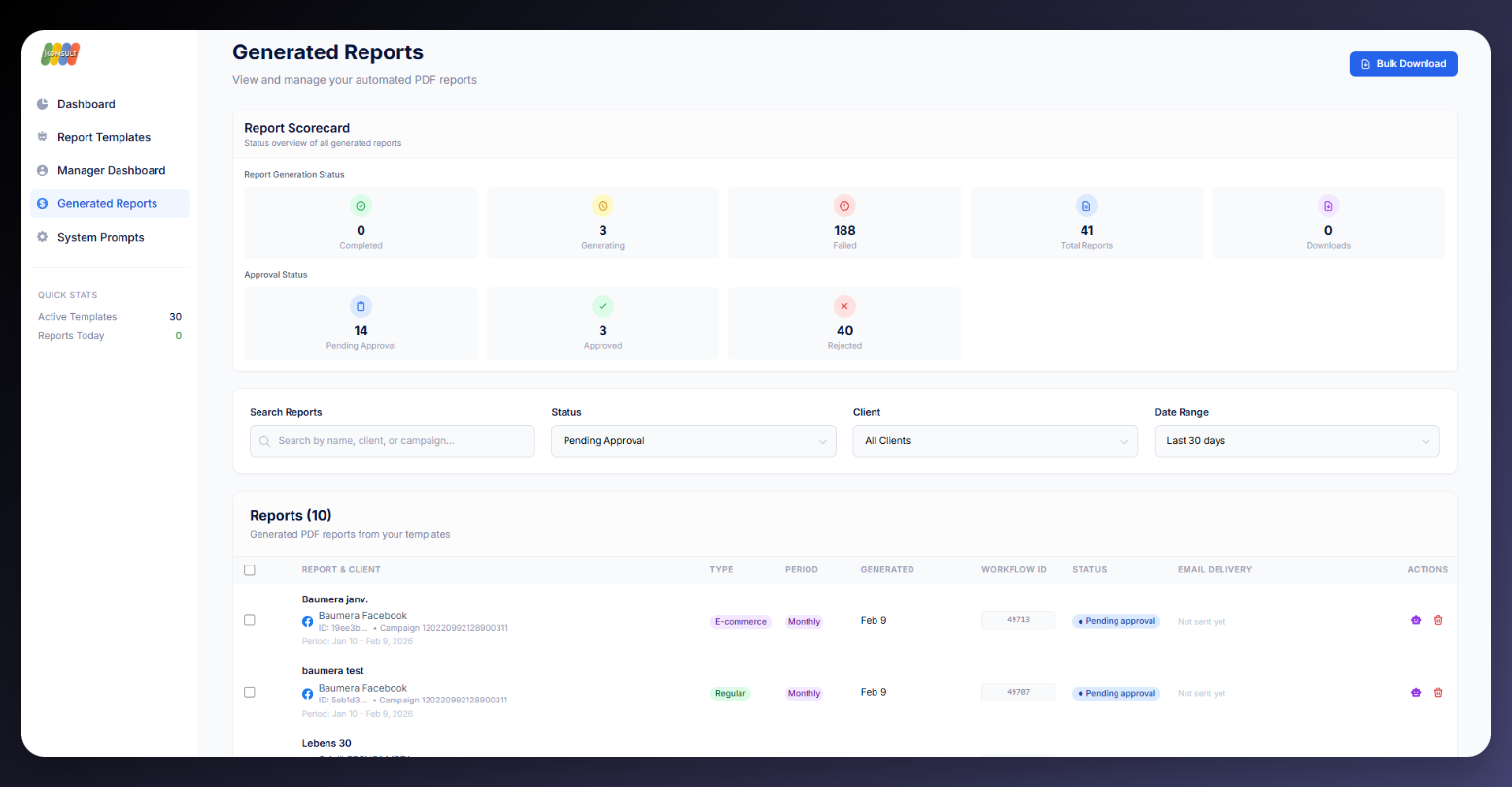
AI Ads Reporting Dashboard
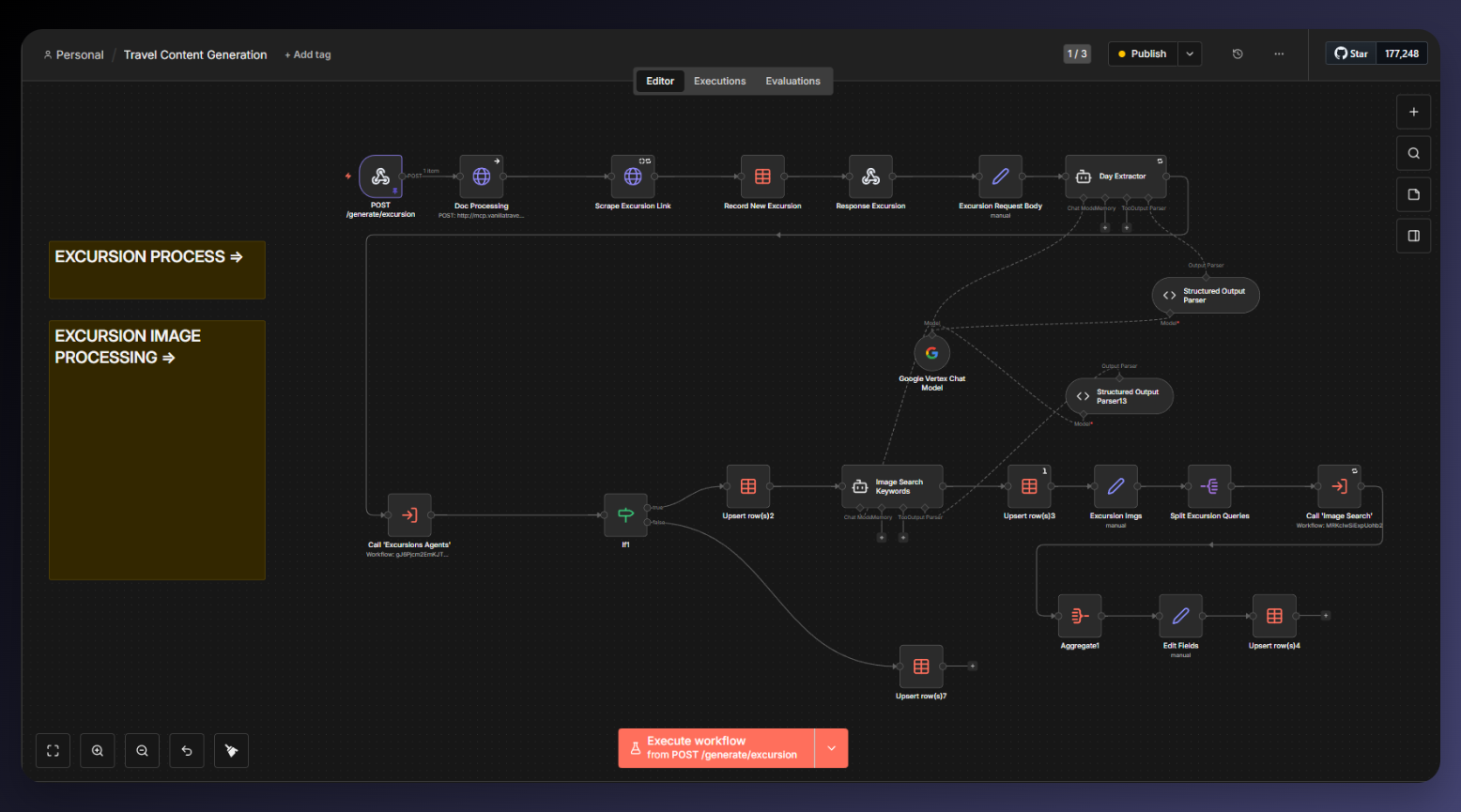
AI Travel Content Engine
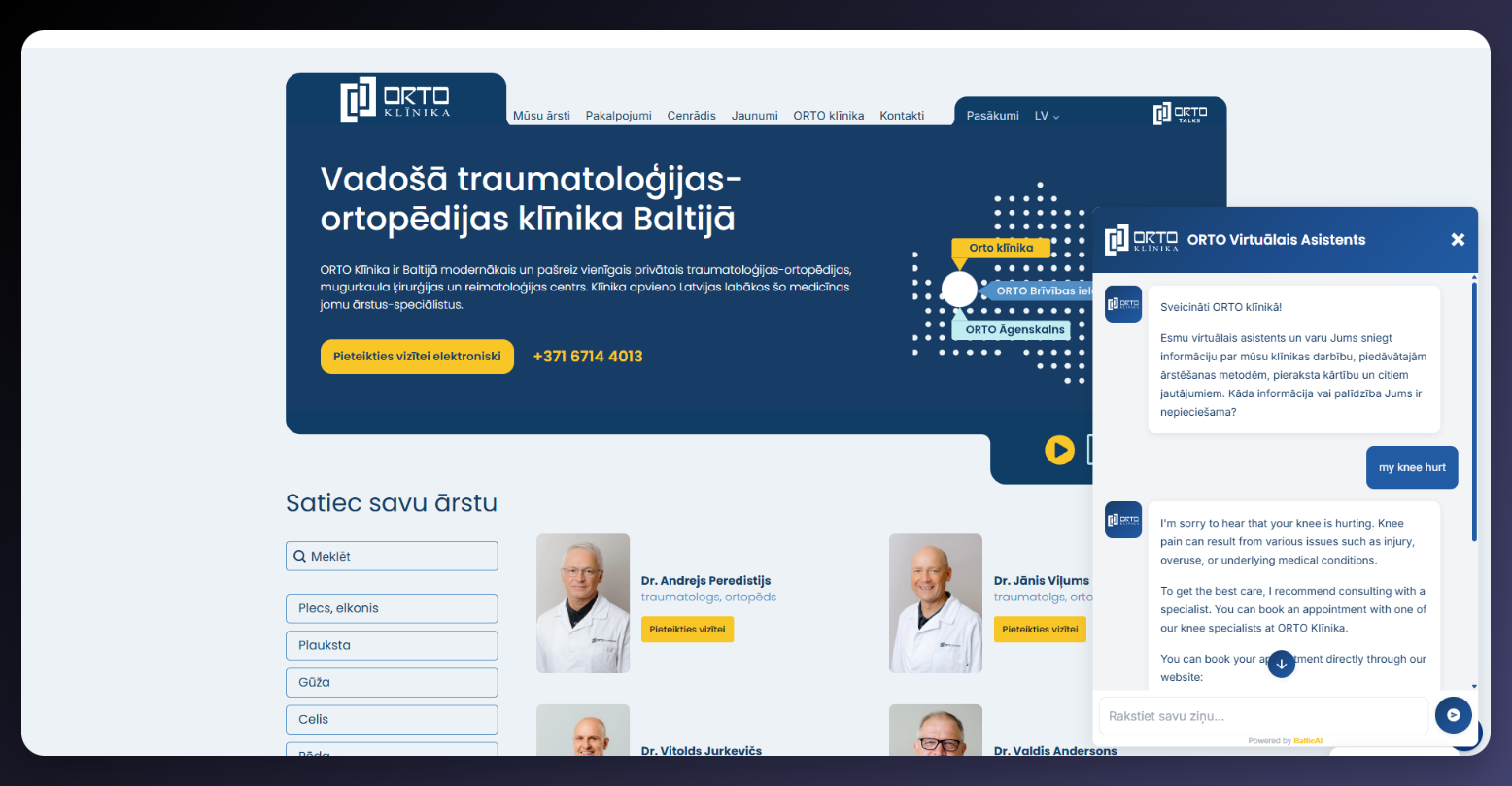
AI Customer Chat Assistant
Business Outcomes First
We don't just ship automations — we ship results. Every engagement tracks time saved, costs reduced, and revenue protected so you see exactly how AI moves your business forward.
Adoption That Sticks
Automation only works if your team uses it. We integrate directly into the tools your people already rely on — so adoption is seamless and results don't erode after go-live.

Compliance-Ready by Default
Security and access controls are built in from day one — not bolted on later. Your legal and compliance teams can approve faster because the foundations are already right.



Ongoing Optimization Included
We don't disappear after delivery. We monitor performance, fine-tune automations as your business evolves, and continuously improve results — turning a one-time win into compounding gains.
24/7 Workflow Automation
Automated agents handle repetitive tasks end-to-end — qualifying leads, triaging support requests, processing orders — so your team focuses on work that grows revenue.
Real-Time Performance Tracking
See exactly how automation is impacting your business. Response times, tasks handled, cost savings — live dashboards make every result visible and accountable.
Secure Knowledge Access
Your team gets instant answers from your own internal documents and data. No more searching through folders — answers come from your verified sources, not guesswork.
Supervised Handoff Controls
Your team stays in control. When automation reaches a decision that needs human judgment, it routes to the right person immediately — no dropped tasks, no missed signals.
Enterprise-Grade Data Security
Your data never leaks. Role-based access means each person sees only what they need, and every automated action is logged — so you're always audit-ready.
Works With Your Existing Tools
We connect directly to the tools your team already uses — CRM, helpdesk, ERP, Slack — so automation delivers results in the systems your business runs on today.











